Podcast RAG System with Vector Search
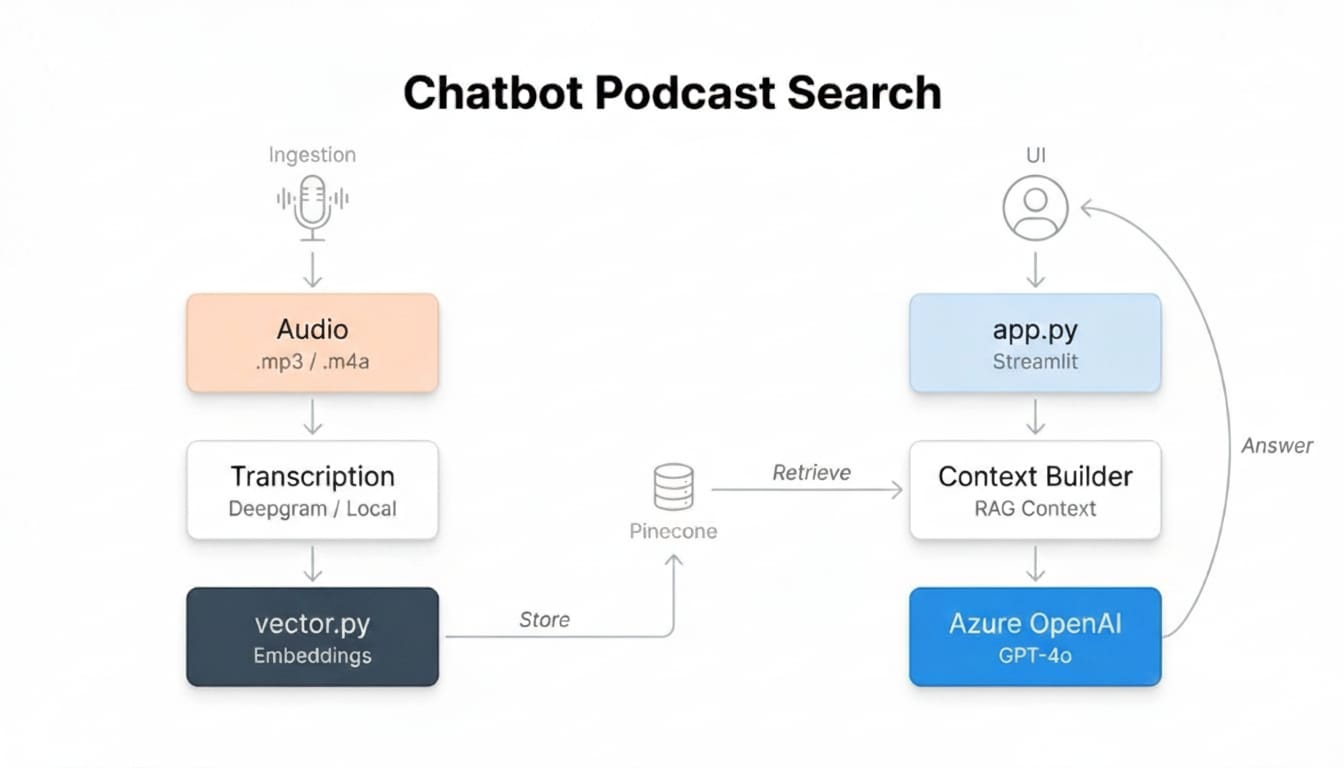
I built a complete RAG system that automatically downloaded podcast episodes, transcribed audio using Deepgram, generated vector embeddings, and stored them in Pinecone for semantic search. Users ask questions in natural language and receive contextually grounded answers from actual podcast content — not hallucinations.
Implemented the full pipeline end-to-end: audio ingestion, transcript chunking strategy, embedding generation, vector indexing, retrieval logic, and prompt engineering for accurate, citation-backed responses. Built a Streamlit interface that displays indexed episodes and enables conversational exploration of the knowledge base.
PM Takeaway: The hardest product decision in RAG isn't choosing the vector database — it's chunking strategy. Chunk too small and you lose context; chunk too large and you lose precision. This project gave me hands-on understanding of the cost-performance-accuracy triangle that every RAG product team navigates.


Faizan didn't just study AI products — he built them.